Wednesday, February 29, 2012
End of clickmaniac
Clickmaniac is quickly winding down.... Remember that we'll start class today with a viewing & discussion of the results. So, please make sure someone from your teams is present to be able to comment on what worked and what didn't...
Tuesday, February 28, 2012
The Golden Ratio φ and the Fibonacci Numbers
 While mathematicians can be proud of π (or rather τ, because π is wrong),
and physicists can claim the fine structure constant α-1 (≈137), I
would like to claim φ for the computer scientists.
While mathematicians can be proud of π (or rather τ, because π is wrong),
and physicists can claim the fine structure constant α-1 (≈137), I
would like to claim φ for the computer scientists.
Being the golden ratio and all, it's pretty awesome. As Vi Hart explains in
her video, the angles between leaves
on a plant, the number of petals on a flower, and the number of grooves on a
cone all follow the tenets of "the most irrational number" φ, which
is bounded by the ratios of adjacent Fibonacci numbers. φ is also the only
number for which φ2= φ+1 or changed slightly, φ2-φ-1=0,
which we can solve using the quadratic formula. We get

 Plants weren't the only organisms
to use Fibonacci numbers. In colonies of bees, drones will have 1 parent (the
queen), whereas queens will have 2 (the queen and a drone). So a drone's family
tree has 1 parent, 2 grandparents, 3 great-grandparents, and so on. That's
pretty trivial, but how would you explain that a DNA molecule is approximately
34 angstroms long by 21 angstroms wide? Or that the ratio of lengths of the two
subdivisions of the bronchi is 1:1.618. If you want something a little more
touchable, the proportions of the human body, are all in line with the golden
ratio. From the organization of our face (i.e. the distances between our eyes
and chin) to the length of our limbs, to the perfect human smile, the golden
ratio plays a well-noted role in our body's measurements.
Plants weren't the only organisms
to use Fibonacci numbers. In colonies of bees, drones will have 1 parent (the
queen), whereas queens will have 2 (the queen and a drone). So a drone's family
tree has 1 parent, 2 grandparents, 3 great-grandparents, and so on. That's
pretty trivial, but how would you explain that a DNA molecule is approximately
34 angstroms long by 21 angstroms wide? Or that the ratio of lengths of the two
subdivisions of the bronchi is 1:1.618. If you want something a little more
touchable, the proportions of the human body, are all in line with the golden
ratio. From the organization of our face (i.e. the distances between our eyes
and chin) to the length of our limbs, to the perfect human smile, the golden
ratio plays a well-noted role in our body's measurements.
Perhaps it shouldn't be
surprising then, that there is a theory that the universe is shaped as a
dodecahedron, which is in turn based on φ. Or that even in the nanoscale world,
the frequencies of magnetic resonations are in the ratio of φ. The "magic"
of this number hasn't escaped human attention. Leonardo da Vinci, Michelango,
and Rapheal all used the golden ratio in their work. (I don't know about
Donatello) Dimensions in architecture from the Pyramids to the Parthenon to the
U.N. building have all been inspired by φ.

Within optimization techniques,
the golden section search uses φ to find extremum of unimodal functions; within
financial markets, φ is used in trading algorithms. In my humble opinion, I'm
still skeptical of φ for all its glory, because there is an underlying force
that simply results in φ (as Vi Hart considers in her third Plant video). But
the golden ratio will certainly see much more use in human civilization because
of its sheer usefulness. For more on the ubiquity and beauty of φ, I strongly
suggest the following video:
"This pattern is not just useful, not just beautiful, it's inevitable. This is why science and mathematics are so much fun! You discover things that seem impossible to be true and then get to figure out why it's impossible for them not to be." - Vi Hart
References:
Oracle ThinkQuest's The Beauty of the Golden Ratio
Monday, February 27, 2012
Would an Isolated Network Suppress its Load by Connecting to Another Network?
Yes, but only up to a critical
point. A group of mathematicians from University of California Davis has recently
built a model to analyze how interconnection between networks could amplify
large global cascades by spreading failure. It is a surprise because
conventional wisdom suggests that having more interconnections provides more
routing options to handle unexpected high loads. A failed connection could
divert its loads to neighbors with lower loads, using the whole system more
effectively.
This topic relates to the materials we are currently studying in class: Braess’ paradox, load balancing, and routing game. Generally, people believe that having more resources and options are better than nothing. For example, one could imagine that building a new freeway could reduce traffic on another freeway that has similar destinations. Examples seen in class showed that when a better resource is provided, every individual chooses that option. Because each person is selfish and not willing to give up the best benefit, it reduces overall performance. (http://en.wikipedia.org/wiki/Braess's_paradox) Although there are benefits to creating interconnections, having an interdependent network could increase the chance of weakening the entire network.
For each interconnection that is added, additional load is expected, thus resulting in greater total capacity and average capacity. When one connection fails, it will divert its load by passing it to neighboring networks. Neighboring networks need to suddenly handle excess loads and as a result, have a higher chance of failing as well. In this way, having one failed connection in a network could cause a cascade of loads in the whole system.
The paper published by Charles Brummit’s group studied the topologies of the interacting networks. They analyzed topological data on two interdependent power grids from the US Federal Energy Regulation Commission (FERC). Additionally, Brummit’s team developed a multitype branching process approximation as a theoretical tool to formulate the cascade spreading in interconnected networks, which is justified to be the ideal model for power grids in this paper.
One of the important results they found in the paper is, “What amplifies the global cascades most significantly is the increase in total capacity (and hence average load available for cascades) and not the increased interdependence between the networks.” This explains why people observe network failure cascades happening in real life. Since it’s more common to open a connection from one network to others than to rewire a connection to connect to other networks, the former increases the overall loads of the system, thus more vulnerable to cascades. Load balancing and determining the optimal configuration of interconnection of networks are very challenging yet useful topics to study.
Source:
http://www.itworld.com/networking/253082/science-too-many-connections-weakens-networks
http://www.pnas.org/content/early/2012/02/15/1110586109.full.pdf
This topic relates to the materials we are currently studying in class: Braess’ paradox, load balancing, and routing game. Generally, people believe that having more resources and options are better than nothing. For example, one could imagine that building a new freeway could reduce traffic on another freeway that has similar destinations. Examples seen in class showed that when a better resource is provided, every individual chooses that option. Because each person is selfish and not willing to give up the best benefit, it reduces overall performance. (http://en.wikipedia.org/wiki/Braess's_paradox) Although there are benefits to creating interconnections, having an interdependent network could increase the chance of weakening the entire network.
For each interconnection that is added, additional load is expected, thus resulting in greater total capacity and average capacity. When one connection fails, it will divert its load by passing it to neighboring networks. Neighboring networks need to suddenly handle excess loads and as a result, have a higher chance of failing as well. In this way, having one failed connection in a network could cause a cascade of loads in the whole system.
The paper published by Charles Brummit’s group studied the topologies of the interacting networks. They analyzed topological data on two interdependent power grids from the US Federal Energy Regulation Commission (FERC). Additionally, Brummit’s team developed a multitype branching process approximation as a theoretical tool to formulate the cascade spreading in interconnected networks, which is justified to be the ideal model for power grids in this paper.
One of the important results they found in the paper is, “What amplifies the global cascades most significantly is the increase in total capacity (and hence average load available for cascades) and not the increased interdependence between the networks.” This explains why people observe network failure cascades happening in real life. Since it’s more common to open a connection from one network to others than to rewire a connection to connect to other networks, the former increases the overall loads of the system, thus more vulnerable to cascades. Load balancing and determining the optimal configuration of interconnection of networks are very challenging yet useful topics to study.
Source:
http://www.itworld.com/networking/253082/science-too-many-connections-weakens-networks
http://www.pnas.org/content/early/2012/02/15/1110586109.full.pdf
Going Mobile
From texting a friend to looking up reviews for a certain
restaurant, society is increasingly incorporating smartphones into their daily
lives. No longer a luxury, smartphones have become cheaper, faster, and more
versatile. According to Nielsen’s third quarter survey of mobile users,
smartphone ownership has reached 43% of all U.S. mobile subscribers; the use of
smartphones has steadily been increasing, with a majority of people under the
age of 44 now using smartphones.
Recently,
Google partnered with Ipsos to research how consumers use their smartphones and
published their findings in “Our Mobile Planet: Global Smartphone Users.” Not
only did they find that smartphone ownership has jumped globally, they found
that consumers are constantly using their mobile devices. From their home to
public transportation, people are frequently using their smartphones to access
the internet to look up local content.

As a result of the increasing popularity of smartphones,
advertisers are shifting to mobile devices as their new platforms. In Korea, a
study has shown that Koreans spend an average of 79 minutes per day using their
mobile devices (excluding calls and texts), while spending an average of 75
minutes per day watching television. With smartphones now capable of streaming
movies and television shows, people are slowing replacing televisions as a
source of entertainment/information. For advertisers, mobile ads are more
attractive as they do not need to worry about limitations on time. Also,
instead of spamming commercials with hopes that they will reach the correct
audience, advertisers can easily tailor advertisements to target specific users,
similarly to online advertising.
Currently, with the help of their Android devices, Google is
dominating the mobile advertisement market. Competitors such as Apple have cut
the minimum price it charges advertisers to run iAd mobile ads to better
compete with Google. And recently, another advertising giant has decided to
enter the fray: Facebook. On February 1, 2012, Facebook signed a deal with
Bango, a firm that deals with mobile payment services, and is expected to
announce its advertising plans this Wednesday in New York. With over 425
million members accessing Facebook through smartphones and tablets, Facebook
will be pursuing mobile advertising as a source of revenue. While they have
stayed quiet on their plans, there is speculation that Facebook is testing ads
that appear like status updates on the news feed. Though they could be
alienating users by bombarding them with ads, the payoff could be huge;
MobileSquared, a British research firm, estimates that Facebook could possibly
generate $653.7 million in the United States alone. As Google’s research has
shown, in order for businesses to reach consumers in the future, they must go
mobile.
Sources:
The Risk of Using Link Farms
The goal of any website is to be the highest rated search
when certain keywords are typed in. With Google becoming the primary used
search engine worldwide, this has meant that websites need to be highly ranked
by Google, or else risk not being found. Having a large number of websites link
back to your site is an easy way for a site to increase its page rank.
Unfortunately, sites won’t just link to your site for no reason. Unless you
have content that is relevant to their webpage there is no reason for a link to
be created.
There is another way however. What if a series of sites
could promise you that they would link to your site, if you would link to
theirs? This would be an easy way for you to increase links to your page and
therefore, your page rank. This is why link farms have become popular. In
theory it takes nothing but signing up and adding irrelevant links to your site
to get many links heading back to your website. The result of this can lead to
you rocketing up the organic search results. Unfortunately, getting caught
using these practices can lead to a Google created punishment.
The worst of these punishments was handed down to BMW for
using a series of “doorway pages” to bolster the rank of its German site
BMW.de. They were given the web version of the death penalty-removal from the
Google search results. However, most of the time the punishments are far more
tame. JC Penny was caught with thousands of paid links used to rank and the
result was just a drop from being the number one search result to around 70th
for certain searches like “living room furniture”. The drop in rank occurred over two hours. In
an effort to stave off a harsher punishment JCPenny fired its search engine
consulting firm (those are necessary now).
Due to the widespread use of the internet web sites have
become valuable. In an effort to increase traffic and to show up sooner on a
search result it has become more and more important to have a highly ranked
website. This has made Google’s PageRank formula as well as its spam detection
formulas hot commodities. Knowing how to increase rank, or how to cheat without
getting caught, could end up generating tons of revenue for a company. This has
made using LinkFarms profitable but only if you can avoid Google detection.
References:
Sunday, February 26, 2012
Trends in Digital Advertising
Online advertising is quickly becoming the most popular form
of advertisement. For example, Facebook is currently about to integrate
“Premium Ads” into their system. These Premium Ads will include more “social
context” which means that “the friends of the people who are fans of a
particular product that advertises on Facebook – not just those who have hit
the “Like button for that brand – will see an enlarged version of the product’s
advertising”. With new focuses on ads in many social networks, we can see many
trends that have emerged in the past decade.
First is paid search advertising. This is a type of
contextual advertising where companies pay search engines to link their ad for
certain keywords. Each time the company’s ad is clicked, the company pays a
certain amount of money to the search engine.
In the world of paid search advertising, Google is the leader of the
pack. Google’s share of the paid search market is almost 80%.
Another trend is organic searches. An organic search is a search
that generates results that are not paid advertisements. While organic searches
may seem to hinder paid search advertising revenue, it has been found that
organic searches actually increase the rate that a paid ad is clicked on. NYU
Stern professors have found that “on average, the impact of organic listings on
paid advertising is 3.5 times stronger than vice-versa, possibly because of the
tendency of consumers to trust organic listings more than paid ads”.
Social media advertising is an obvious trend. In the 2000s,
we’ve seen many social networks, such as Myspace, Facebook, and Twitter, rise
to power. Companies now see these social media websites as an excellent place
to market their products. As popularity in social media rises, so does the
popularity of advertising in social media. In the Facebook example, we see that
Facebook has decided to focus more efforts into advertising. As their global
user growth rate is slowing down, they need more viewers and to make each ad as
valuable as possible. Facebook’s current ad revenue is $3.15 billion, and they
are hoping to increase this to as much as $100 billion. Another example of social media advertising is
Twitter. Ads on Twitter are a little different from ads on other social media
sites. The ads on Twitter are integrated into the system as “Promoted Tweets”.
Advertisers buy the “Promoted Tweets” and whenever a Twitter user searches a
specific keyword, that promoted tweet will be the top result. This advertising
plan is expected to make $150 million in advertising revenue for Twitter this
year.
These trends that we have observed in the last decade have
changed the world of advertising. It is predicted that by 2020, there will be 5
billion Internet users, compared to 1.7 billion now. As more people have Internet
access, advertisers will find new ways to cater to those individuals’ interests
and set more trends in online advertising.
Sources:
http://bits.blogs.nytimes.com/2011/01/24/twitters-advertising-plan-could-be-paying-off/
http://www.webpronews.com/does-an-organic-search-presence-help-paid-result-performance-2009-12
http://www.smh.com.au/technology/facebook-risks-alienating-users-with-new-ads-20120225-1tuvf.html
Saturday, February 25, 2012
Anonymous Communication via the "Bus" method (A follow up to the earlier TOR post)
After reading the post on TOR, I felt compelled to right about this!
The purpose of TOR (onion routing) is to provide a means of anonymous communication.
The reason we need a means of anonymous communication is as such: currently, we have excellent methods of “encrypting” messages sent between pairs! However, although encryption makes it such that the content of a message is hidden, it is still possible to determine who is communicating, and an adversary can cut off communication between a communicating pair (this would be extremely detrimental in say making an important business transaction, or to take it a step further, covert military operations).
As the writer of the TOR post stated, TOR is an example of onion routing, where using successive layers of encryption each router (“onion router”) only knows its predecessor and successor but not the overall route. However, there is a problem with this type of routing! It is possible to observe traffic flows at the ends of the network so attackers can in some instances deduce whether or not two entities are communicating. (ref 2)
A model to improve the degree of anonymity is the busing model (which is in fact inspired by the real-life public transportation system which is used by people without vehicles, such as myself). The possible senders and receivers can be represented as bus stations and the information they are sending as passengers. This idea can be applied to the digital world by having a “bus” traverse through a network of n nodes, where node i sends a message destined for node j with probability p to a bus of m seats. The reason this model is anonymous is because the traffic pattern is fixed, and “passengers” (information) cannot be observed getting on and off the bus. (ref 1)
This model has yet to be used for significant practical purposes. One of the biggest obstacles in implementing this model is that with this setup is there are only a limited number of seats (resources) on the bus so it is possible a message sent by a node will overwrite a message sent by a previously visited node yet to reach its proper destination.
In fact, I am doing research regarding this model and as a SURF (hopefully, I guess I figure out April 1st) I am exploring ways to make this model feasible (to provide robustness against this problem of “overwriting” while keeping the amount of resources constant; in fact I feel I have found some improvements so if this subject interests you post comments and I will happily answer your questions).
Anyways, I couldn’t pass up a chance to talk about this; this is my current (and only) area of research so I give a special thanks to the person who wrote the TOR post which allowed me to talk a bit about the busing model for anonymous communication!
A few pertinent references:
1)Beimel, A., Dolev, S.. Buses for Anonymous Message Delivery. In 2nd International Conference on FUN with Algorithms, pages 1-13, Carleton University Press, 2001.
2)Roger Dingledine, Nick Mathewson, Paul Syverson. Tor: The Second-Generation Onion Router. Usenix Security 2004, August 2004.
The purpose of TOR (onion routing) is to provide a means of anonymous communication.
The reason we need a means of anonymous communication is as such: currently, we have excellent methods of “encrypting” messages sent between pairs! However, although encryption makes it such that the content of a message is hidden, it is still possible to determine who is communicating, and an adversary can cut off communication between a communicating pair (this would be extremely detrimental in say making an important business transaction, or to take it a step further, covert military operations).
As the writer of the TOR post stated, TOR is an example of onion routing, where using successive layers of encryption each router (“onion router”) only knows its predecessor and successor but not the overall route. However, there is a problem with this type of routing! It is possible to observe traffic flows at the ends of the network so attackers can in some instances deduce whether or not two entities are communicating. (ref 2)
A model to improve the degree of anonymity is the busing model (which is in fact inspired by the real-life public transportation system which is used by people without vehicles, such as myself). The possible senders and receivers can be represented as bus stations and the information they are sending as passengers. This idea can be applied to the digital world by having a “bus” traverse through a network of n nodes, where node i sends a message destined for node j with probability p to a bus of m seats. The reason this model is anonymous is because the traffic pattern is fixed, and “passengers” (information) cannot be observed getting on and off the bus. (ref 1)
This model has yet to be used for significant practical purposes. One of the biggest obstacles in implementing this model is that with this setup is there are only a limited number of seats (resources) on the bus so it is possible a message sent by a node will overwrite a message sent by a previously visited node yet to reach its proper destination.
In fact, I am doing research regarding this model and as a SURF (hopefully, I guess I figure out April 1st) I am exploring ways to make this model feasible (to provide robustness against this problem of “overwriting” while keeping the amount of resources constant; in fact I feel I have found some improvements so if this subject interests you post comments and I will happily answer your questions).
Anyways, I couldn’t pass up a chance to talk about this; this is my current (and only) area of research so I give a special thanks to the person who wrote the TOR post which allowed me to talk a bit about the busing model for anonymous communication!
A few pertinent references:
1)Beimel, A., Dolev, S.. Buses for Anonymous Message Delivery. In 2nd International Conference on FUN with Algorithms, pages 1-13, Carleton University Press, 2001.
2)Roger Dingledine, Nick Mathewson, Paul Syverson. Tor: The Second-Generation Onion Router. Usenix Security 2004, August 2004.
Side Effect of the Growing Social Network
Many of the the benefits of the growing social network have been discussed, and there are others as well that have not yet been brought up. However, as with just about anything in life, there will be undesired consequences to change. One of the biggest issues with with sites such as Facebook and Youtube is their inherent intrusion into privacy. Even someone who regards their individual privacy highly and has never created an account with one of these sites has almost undoubtedly had themselves featured in a photo or video for hundreds of people to see. Whereas most institutions are required to have you sign a waiver allowing you to be featured in their media, for individual users on Facebook or Youtube there is no such requirement.
A recent troubling trend is that young individuals, who may not be aware of what they are getting into, have themselves been breaking apart the shelter provided their family, as evidenced by this recent article. Children, by posting videos of themselves on Youtube, are casting themselves into the real, cynical world, often before they have matured to the point of being ready to handle the unfiltered opinions of people hiding behind the anonymity of the Internet. This only reinforces the argument for recent Internet-restricting bills. The question then becomes, does the responsibility for issues such as these fall on the family of the children, for letting videos such as these get posted, or on the Internet itself, for providing a medium for anonymous users to criticize without moral repercussions?
A recent troubling trend is that young individuals, who may not be aware of what they are getting into, have themselves been breaking apart the shelter provided their family, as evidenced by this recent article. Children, by posting videos of themselves on Youtube, are casting themselves into the real, cynical world, often before they have matured to the point of being ready to handle the unfiltered opinions of people hiding behind the anonymity of the Internet. This only reinforces the argument for recent Internet-restricting bills. The question then becomes, does the responsibility for issues such as these fall on the family of the children, for letting videos such as these get posted, or on the Internet itself, for providing a medium for anonymous users to criticize without moral repercussions?
Friday, February 24, 2012
Facebook Ads: Exploitations in CPM and CPC
Article: http://talk.adaptly.com/post/6494339698/some-facebook-impressions-are-more-equal-than-others
Facebook offers two basic kinds of payment schemes for
ads. The first is cost per 1000 impressions (CPM), which is when advertisers
pay solely based on how many times the ad has shown up on consumer pages. The second
is cost per click (CPC), which allows the advertiser to pay a fixed amount only
when the ad is clicked. Both have advantages in certain situations depending on
the demographics of the targeted audience as well as the top priorities of the
advertiser, as we will discuss below.
CPC
and the “test” phase
Remember that Facebook will always try and
maximize its own revenues. It usually (excluding special cases which will be
discussed later) achieves this by running an auction in which it displays the
ads that have the highest CPM. In order to bid CPM and CPC ads with each other,
Facebook likely uses some form of the naïve conversion from CPC to CPM, which
is to take the expected value of a CPC ad: CPM = CPC * CTR / (1000 impressions),
where CTR is the click through rate of the ad for the user viewing the page (clicks
per impression).
Of course, no one knows an ad’s true CTR at any given time. Therefore, when a CPC ad is first
created, there’s a great deal of uncertainty in how the ad will perform, especially
if the target audience has diverse demographics. Because of this, Facebook puts
the ad through an initial “test” phase, in which it monitors the ad’s
performance closely. If the CTR of the ad turns out to be terrible (e.g. 0
clicks for the first 10,000 impressions), then the ad is eventually pushed out
of rotation and no longer displayed.
In some sense, this is an exploitable property of
Facebook’s auction system; one could theoretically create an ad with an
incredibly low CTR and run a CPC ad. Using this strategy, the advertiser would
succeed in getting many impressions and a high reach at a very low cost by repeating
the above strategy over and over again (although it is unclear whether or not
Facebook detects this and blacklists or penalizes poor performing
advertisers).
With respect to everything mentioned above, keep in
mind this is not to say CTR’s don’t matter for CPM ads: they still do! If
Facebook knows that a CPM ad has a very low CTR, it might even consider just
not showing the ad and instead showing an in-house ad. Remember that Facebook’s
goal is to maximize its long term revenues; if ad quality is low and users are
not happy with what they’re seeing, they’re more likely to install ad blockers or
to simply stop clicking on ads. Therefore, it is important for CPM ads to also maintain
a reasonable CTR in order to stay in rotation.
Why
CPC?
In addition to the possible exploitation above, CPC ads
are also good for getting Facebook to target your ads for you. The Adaptly article
above details an experiment in which they switched ads from CPC to CPM. The
results showed that the difference in CTR for both ad modes was on the factor
of ~15! This demonstrates that Facebook is almost certainly automatically targeting
CPC ads to users that it thinks would be interested in the particular subject.
In terms of ad metrics, this means that CPC ads have higher CTR’s and are also
more likely to generate likes.
Interestingly, the first article mentions that expert
optimizers often convert their extremely high performance ads to CPM, the
reason being that advertisers rarely pay less than their CPC bid.
Why
CPM?
CPM ads allow for the advertiser to reach the largest
audience possible while sacrificing the Facebook-internal targeting benefits that come along with
CPC. Because of this, CPM ads tend to have lower CTR’s and connection rates.
They do, however, require a bit more attention on advertiser’s part because it
is in the best interest of the advertiser to bid as low as possible in CPM,
simply because the CPM bid has no effect on how well the ad performs. This contrasts
with CPC ads in which the higher the bid, the more likely the ad reaches a
correctly targeted individual.
Because every advertiser’s situation differs, it is
obviously impossible to generalize on whether CPC and CPM is more effective.
Rather, it is more important that each advertiser choose the appropriate
strategy to minimize their CPX, where X is the metric that they are attempting
to maximize.
Surprise! People Hate Ads on Their Phones
Mobile apps are going through an
expansion so rapid that many are comparing the growth of this nascent industry
to the early days of the dot-com bubble.
Some have taken this analogy so far that they have proclaimed that “for
mobile apps, it’s 1996 all over again.”[1]
One key difference, though, is that today’s consumers bare battle scars
from nearly two decades of exposure to obnoxious pop-up ads and blinking
banners. So although it may seem
like 1996 for mobile apps, the 1996-era naïveté of the consumer has long since
vanished, leaving bitter, ad-adverse veterans of the web.
Much of the Internet is powered by advertisement-derived revenue, and many take for granted the fact that ads, at least in their current incarnation, will continue to generate the kinds of profits that they historically have. A recent survey of American and British Internet users calls this assumption into question, highlighting the dwindling efficacy of Internet-based ads, particularly those served on mobile platforms. While it is not particularly astonishing that ads in general have seen a downturn in terms of click through rate, the much more surprising result is the utterly vehement response of those surveyed to the ads served through their phones.
A phone is more intimate than a computer (after all you carry it everywhere, keep it in your pocket, and press it to your face) and it could be that this special relationship that people have with their phones makes ads seen on them all the more appalling. The following graph shows what percentage of survey respondents found ads served through different platforms to be invasive and unwanted.
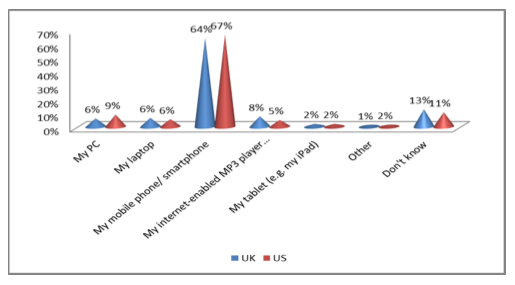
Shockingly, ads seen on phones are over ten times more offending than
those seen while browsing on a traditional computer.[2] Essentially, people see their phones as a private, personal
space and the ads served through them are just revamped, 21st
century versions of the universally hated telemarketer.
Maybe, then, it really is more like 1996 for mobile apps than we thought. The dot-com bubble was fueled by the idea that a website’s getting “eyeballs” would directly equate to revenue, and when this turned out to not be true, many Internet businesses failed. Today we see over 500,000 apps in the Apple App Store, many of which are free and are operating under the assumption that if enough people get that app, traditional Internet advertising methods can be used to cash in on the resulting user base.[3] The public, however, seems to find phone ads highly unappealing, so unless a better way to monetize these apps is found, it may become 2000 for mobile apps sooner than we think.
Sources:
1. http://techcrunch.com/2011/02/19/mobile-apps-1996-all-over-again/
2. http://techcrunch.com/2012/02/24/first-look-survey-warns-of-consumers-turning-off-from-digital-ads/
3. http://www.gottabemobile.com/2012/02/24/apple-making-it-easier-to-find-awesome-apps-with-chomp/
Clickmaniac Deadline TONIGHT!
Class, please remember that the deadline to create your ads is midnight tonight (you've had a whole week to work on creating your ads, so we hope you have done enough!)
The homework has exact details on what edits you can/can't do to your ads after tonight, but to summarize, you can change your targeting, and bid type and bids, but nothing in "Section 1" can be changed! Note that changing targeting could still require re-approval by Facebook.
Of course, these rules apply to us TAs as well.
The homework has exact details on what edits you can/can't do to your ads after tonight, but to summarize, you can change your targeting, and bid type and bids, but nothing in "Section 1" can be changed! Note that changing targeting could still require re-approval by Facebook.
Of course, these rules apply to us TAs as well.
Ad Targeting: Beyond Facebook
Now in the middle of Clickmaniac, I think most teams have discovered just how important ad targeting is. Ad targeting is the secret to achieving a high Click-through Rate (the ratio of clicks to total impressions). It comes as no surprise then that more and more attention is being paid to how audiences are selected and targeted. Just a few weeks ago, facebook added a new feature allowing marketers to target Hispanic users [1]. If go to create your own ad, select the broad targeting option, and you will see an "Ethnic" tab. Currently, "Hispanic" is the only option within this tab, and it's not entirely clear how facebook is identifying who is Hispanic. What's interesting to note is that, unlike most other ways that facebook ads are targeted, a user doesn't supply his or her own "Hispanic status." Rather, facebook must somehow calculate this based on a user's profile.
As anyone who has created a facebook ad has seen, the site allows ad-creators to target users based on location, age, interests, education, and connections (to the page being advertised) (with more ethnicity options possibly to follow). Another way that advertisers select their audiences is through behavioral targeting. Behavioral targeting is when a company keeps track of a unique user's online behavior, like what searches they make and what links they click on, and then uses that information (or profile) to target ads [2]. This technique works very well; behaviorally targeted ads can be more than twice as effective as non-targeted ads [3]. Target is one company that has invested a lot of time and effort into behavioral targeting technology. By tracking customer's purchases, their statisticians were able to discover patterns that indicated the likelihood a given customer was pregnant [4]. They could then send coupons and ads for baby supplies to specific people. In one case, Target figured out that a high school girl was pregnant before her father did [4, page 7].
Finally, we can see how pervasive ad targeting has become by the fact that it is starting to leave the digital sphere. In London, a new ad-system is being used on the city side walks. The display system uses facial-recognition technology to display different versions of an ad to men and women [5]. While currently only showing up on one street, the new ad-system hints at how widespread ad-targeting could become in the near future.
Sources:
[1] http://www.clickz.com/clickz/news/2153352/facebooks-self-serve-ads-target-hispanics
[2] http://en.wikipedia.org/wiki/Behavioral_targeting
[3] http://www.bizreport.com/2010/03/nai_behaviorally-targeted_online_ads_twice_as_effective.html
[4] http://www.nytimes.com/2012/02/19/magazine/shopping-habits.html?_r=3&pagewanted=1&hp
[5] http://www.pcmag.com/article2/0,2817,2400473,00.asp
As anyone who has created a facebook ad has seen, the site allows ad-creators to target users based on location, age, interests, education, and connections (to the page being advertised) (with more ethnicity options possibly to follow). Another way that advertisers select their audiences is through behavioral targeting. Behavioral targeting is when a company keeps track of a unique user's online behavior, like what searches they make and what links they click on, and then uses that information (or profile) to target ads [2]. This technique works very well; behaviorally targeted ads can be more than twice as effective as non-targeted ads [3]. Target is one company that has invested a lot of time and effort into behavioral targeting technology. By tracking customer's purchases, their statisticians were able to discover patterns that indicated the likelihood a given customer was pregnant [4]. They could then send coupons and ads for baby supplies to specific people. In one case, Target figured out that a high school girl was pregnant before her father did [4, page 7].
Finally, we can see how pervasive ad targeting has become by the fact that it is starting to leave the digital sphere. In London, a new ad-system is being used on the city side walks. The display system uses facial-recognition technology to display different versions of an ad to men and women [5]. While currently only showing up on one street, the new ad-system hints at how widespread ad-targeting could become in the near future.
Sources:
[1] http://www.clickz.com/clickz/news/2153352/facebooks-self-serve-ads-target-hispanics
[2] http://en.wikipedia.org/wiki/Behavioral_targeting
[3] http://www.bizreport.com/2010/03/nai_behaviorally-targeted_online_ads_twice_as_effective.html
[4] http://www.nytimes.com/2012/02/19/magazine/shopping-habits.html?_r=3&pagewanted=1&hp
[5] http://www.pcmag.com/article2/0,2817,2400473,00.asp
Obama's Internet Bill of Rights - Publicity Stunt or a Victory for Privacy Advocates?
In response to widespread criticism of internet giants' Google, Facebook, Yahoo, etc tracking of user information, the government released a set of guidelines it is calling an "Internet Bill of Rights". These guidelines set out to strike a balance between protecting the privacy of consumers on the web from excessive tracking by advertisers and allowing the lucrative internet advertising business to flourish and provide the numerous free web services that rely on advertising as their source of revenue. To this end, this new regulation is currently simply a voluntary agreement between the largest online advertising companies (Google, Microsoft, Yahoo, AOL), which represent ~90% of behavioral advertising, to implement the provisions of the bill. At the moment, the most noticeable change that will occur is that all major web browsers will add, or enhance the functionality of, a "Do Not Track" feature that will signal the web advertisers that a user wishes to opt-out of behavioral advertising, as well as features allowing users to control how their tracking information is used. These new features are a major turnaround for Google, who has stated numerous times that they do not support these kinds of browser-enforced privacy measures.
Naturally, there are widespread criticisms of this new bill, ranging from paranoid crackpot rambling about secret government conspiracies to take over the internet[4], to legitimate concerns regarding the enforceability of this act[2]. At the moment, the main provision of the bill, the "Do Not Track" feature, relies on the very vague clause that "Companies should provide consumers appropriate control over the personal data that consumers share with others and over how companies collect, use, or disclose personal data."[1] As there is no standardized definition of "appropriate", privacy advocate groups have criticized the bill for being too arbitrary and unenforceable. To address such concerns, the Department of Commerce has announced that in the coming weeks it will meet with representatives of the major internet advertisers to develop a code of conduct clarifying exactly what "appropriate" means. Simultaneously, this bill will serve as a template for future legislation that will attempt to make the privacy regulation legally binding.
Overall, this measure has been praised by online privacy groups such as the Electronic Privacy Information Center (EPIC) and Center for Digital Democracy. Given that the Digital Advertising Alliance, the major industry group, fully supports this act, it is likely that it will actually be implemented. The major question to ask is then why would major advertising networks that depend on tracking for their livelihood support such a measure? A number of articles point to the fact that every provision of this bill already exists in some form, and the real issue that very few people actually take the time to "opt-out" from tracking. In this light, this new bill is nothing more than an industry publicity move aimed at calming the recent outcry for internet privacy. I have to disagree with such a negative assessment. It is true that this bill is unlikely to do away with behavioral tracking on the internet, which contrary to the public sentiment, is a good thing. The internet provides an enormous number of very useful services free-of-charge thanks to its ability to target users with ads they might actually be interested in. At the same time, this bill sets an industry rule-of-thumb for the proper use of information gathered online.[2] Just as the "do not call" registry did a great service to many of us in reducing annoying telemarketing without fully eliminating the practice, this bill has the potential to set the industry norm in a very acceptable medium both for internet advertisers and consumers. Enforcing true internet privacy would require a sacrifice of the open internet, which is not something most of us would support, so the next best thing we can ask for is exactly such a good faith agreement of the major players to not abuse the information power they wield.
And really, this is a measure opposed by the Heartland Institute[5], so it can't be that bad of an idea.
[1] "Fact Sheet: Plan to Protect Privacy in the Internet Age by Adopting a Consumer Privacy Bill of Rights." White House Office of the Press Secretary. http://www.whitehouse.gov/the-press-office/2012/02/23/fact-sheet-plan-protect-privacy-internet-age-adopting-consumer-privacy-b
[2] "Obama's Internet Bill Of Rights Will Be Hard to Enforce: Here's Why". PC Advisor. http://www.pcadvisor.co.uk/opinion/security/3339918/obamas-internet-bill-of-rights-will-be-hard-to-enforce-heres-why/
[3] "White House Privacy Bill of Rights Brought to You by Years of Online Debacles". Wired Magazine.
http://www.wired.com/threatlevel/2012/02/privacy-bill-of-rights/
[4] Ken Kaplan "Obama issues Internet Bill of Rights" The Examiner.
http://www.examiner.com/conservative-in-national/obama-issues-internet-bill-of-rights
Naturally, there are widespread criticisms of this new bill, ranging from paranoid crackpot rambling about secret government conspiracies to take over the internet[4], to legitimate concerns regarding the enforceability of this act[2]. At the moment, the main provision of the bill, the "Do Not Track" feature, relies on the very vague clause that "Companies should provide consumers appropriate control over the personal data that consumers share with others and over how companies collect, use, or disclose personal data."[1] As there is no standardized definition of "appropriate", privacy advocate groups have criticized the bill for being too arbitrary and unenforceable. To address such concerns, the Department of Commerce has announced that in the coming weeks it will meet with representatives of the major internet advertisers to develop a code of conduct clarifying exactly what "appropriate" means. Simultaneously, this bill will serve as a template for future legislation that will attempt to make the privacy regulation legally binding.
Overall, this measure has been praised by online privacy groups such as the Electronic Privacy Information Center (EPIC) and Center for Digital Democracy. Given that the Digital Advertising Alliance, the major industry group, fully supports this act, it is likely that it will actually be implemented. The major question to ask is then why would major advertising networks that depend on tracking for their livelihood support such a measure? A number of articles point to the fact that every provision of this bill already exists in some form, and the real issue that very few people actually take the time to "opt-out" from tracking. In this light, this new bill is nothing more than an industry publicity move aimed at calming the recent outcry for internet privacy. I have to disagree with such a negative assessment. It is true that this bill is unlikely to do away with behavioral tracking on the internet, which contrary to the public sentiment, is a good thing. The internet provides an enormous number of very useful services free-of-charge thanks to its ability to target users with ads they might actually be interested in. At the same time, this bill sets an industry rule-of-thumb for the proper use of information gathered online.[2] Just as the "do not call" registry did a great service to many of us in reducing annoying telemarketing without fully eliminating the practice, this bill has the potential to set the industry norm in a very acceptable medium both for internet advertisers and consumers. Enforcing true internet privacy would require a sacrifice of the open internet, which is not something most of us would support, so the next best thing we can ask for is exactly such a good faith agreement of the major players to not abuse the information power they wield.
And really, this is a measure opposed by the Heartland Institute[5], so it can't be that bad of an idea.
[1] "Fact Sheet: Plan to Protect Privacy in the Internet Age by Adopting a Consumer Privacy Bill of Rights." White House Office of the Press Secretary. http://www.whitehouse.gov/the-press-office/2012/02/23/fact-sheet-plan-protect-privacy-internet-age-adopting-consumer-privacy-b
[2] "Obama's Internet Bill Of Rights Will Be Hard to Enforce: Here's Why". PC Advisor. http://www.pcadvisor.co.uk/opinion/security/3339918/obamas-internet-bill-of-rights-will-be-hard-to-enforce-heres-why/
[3] "White House Privacy Bill of Rights Brought to You by Years of Online Debacles". Wired Magazine.
http://www.wired.com/threatlevel/2012/02/privacy-bill-of-rights/
[4] Ken Kaplan "Obama issues Internet Bill of Rights" The Examiner.
http://www.examiner.com/conservative-in-national/obama-issues-internet-bill-of-rights
[5] "Internet ‘Privacy Bill of Rights’ Poses Business Threats" The Heartlander. http://news.heartland.org/newspaper-article/internet-%E2%80%98privacy-bill-rights%E2%80%99-poses-business-threats
Extra lecture this Friday 1-2:30
With all the holidays causing us to miss lectures, I'm going to have to take one extra lecture if I'm going to get through the material you need for the last HW... So, we'll have an extra lecture this Friday Feb 23 at 1-2:30 in ARMS 155 (same time and place as normal). I hope that everyone can make it ... it will be the start of our section on "routing games", which is a particularly fun topic I think.
Thursday, February 23, 2012
Facebook Ad Platform
According to this article, the Facebook ad platform Alchemy has recently been upgraded to work better with Facebook's Timeline and Sponsored Stories features, and it is a tool for creating, managing, and optimizing social advertising campaigns. There are statistics that say a high percentage of marketers will continue to increase their budgets for social media especially because it is still an emerging field in digital advertising. The new upgraded Alchemy will be able to provide marketers with detailed feedback on how their ad campaigns are performing such as information on how ads are performing when shown on pages with the Timeline feature. The platform is expected to expand into the mobile space in the near future, and Facebook may be headed in that direction. Many users access Facebook on mobile devices, so brands are likely to be readily available for advertising in that space.
In an ad campaign, Alchemy would be able to provide ease of ad creation and duplication. It would also provide conversion tracking and analytics at the advertisement level which enable near real time optimization to costs. Considering Clickmaniac, advertising is at a smaller scale with a smaller goal, and this type of platform may not be necessary. Though if we look at making larger and longer ad campaigns, these fine-tuning features that Alchemy provides would be very beneficial in the long run. We see that a platform like Alchemy is another entity in the mix between publishers, advertisers, intermediaries, and users.
http://techcrunch.com/2012/02/23/facebook-ad-partner-experian-launches-new-platform-for-timeline-sponsored-stories/
http://alchemysocial.com/
In an ad campaign, Alchemy would be able to provide ease of ad creation and duplication. It would also provide conversion tracking and analytics at the advertisement level which enable near real time optimization to costs. Considering Clickmaniac, advertising is at a smaller scale with a smaller goal, and this type of platform may not be necessary. Though if we look at making larger and longer ad campaigns, these fine-tuning features that Alchemy provides would be very beneficial in the long run. We see that a platform like Alchemy is another entity in the mix between publishers, advertisers, intermediaries, and users.
http://techcrunch.com/2012/02/23/facebook-ad-partner-experian-launches-new-platform-for-timeline-sponsored-stories/
http://alchemysocial.com/
Advertising and user privacy
With Clickmaniac 2012 well in progress, the students in our class have a chance to take the role of an advertiser. We try to construct ads that cater to specific demographics, and perform analysis to separate the strategies that produces the most clickthroughs from the ones that generates nothing. While this is a very fine (and fun) exercise, when do we stop to consider the people on the other side? How do consumers, data collection, and privacy fit into the equation?
Before going any further, let's review how advertisers collect user information for targeting. Traditionally (unlike Facebook, which simply enumerates your profile), advertising networks set what's known as a "cookie" in your browser to give you a unique identity. There exists two types of cookies--first party cookies and third party cookies. First party cookies are designed to store your browsing state, for instance, if you've logged in to a website or not. These cookies are almost always essential to the proper functionality of a website. Third party cookies, on the other hand, are set by websites from other domains that happen to present content on the current page. In the case of advertising networks, the third party cookies are used to track your web surfing habits. For example, if you visit 5 websites, all of which display ads from a single network (e.g. DoubleClick, owned by Google), that ad network is able to track the exact path through which you move from one site to another. Not all hope is lost for the consumers, however. Many modern browsers implement some sort of privacy controls that allow users to fine-tune their settings pertaining to cookies. Many browsers, like Safari, even have certain privacy protections enabled by default.
Early last week, the Wall Street Journal reported that Google had been bypassing the privacy provisions of the mobile version of Safari for iOS. While the default settings in Safari were to block third party cookies, Google was using a workaround to still set these cookies. The result (one may debate whether this was intentional or not) was that DoubleClick tracking cookies were set, despite the user's preferences. The story caused widespread outrage as to the privacy violations incurred by the internet company. It was later shown that Facebook was doing the exact same thing.
Around the same time last week, The New York Times Magazine ran another interesting story on how one retail chain, Target, was keeping track of customer shopping habits. In addition to assigning each customer a unique ID linked to their name and credit card for in store purchases, Target also obtained data of web surfing and shopping habits of their customers. In fact, the statisticians at Target had so much information from one particular customer's habits that they were able to tell she was pregnant even before her parents knew.
In light of these recent stories, we see that consumer privacy on the internet is still at its infancy. Just like car manufacturers had a responsibility of safety, which led to the seat belt, will internet companies develop responsibilities of their own in terms of protecting a user's personal information? As an advertiser, it's easy to get caught up in pushing the limits when it comes to reaching an audience, but when does it become too much?
Wednesday, February 22, 2012
A Flawed System: Why Human Online Auctions No Longer Work

For even the most skilled human beings, the ability to
constantly observe all of the factors of market pricing, to develop a proper
strategy for using that new information effectively and to act on that new
strategy is impossible to do all within one second. However, that is exactly
what computers are doing today for processing stock market transactions and
online auctions such as online advertising. The speeds of computer transactions
today are sub-second which leaves humans unable to compete effectively. This
gives the human stock market trader a huge disadvantage as they are always
working with false information. As soon as the human trader has seen the
information and has taken the proper amount of time to process it, the market
has already changed because automated computer systems have processed thousands
of transactions on the old data already.
So one
might assume that human traders will one day be phased out of this process
which seems to indeed be the trend. 70% of all equity trades are already done
by high speed computers. But technology already seems to be taking over human
action in many aspects of our lives from automated bill pay to using credit
cards and cell phones instead of cash. So what is the problem with the stock
market and online auctions being computerized? The answer is complex but
essentially comes down to two reasons: Equilibriums and Immaturity. The
transactions that are being done by these high speed computers are done so
quickly that market equilibriums and therefore overall market stability are
never being reached. Data collected from a Chicago firm saw that over 1800 sub-second
price spikes occurred in the last five years due solely to high speed computer
trading. While the overall effect has been fairly mild and the market has
recovered from each, analysts predict that the more algorithms and computers
are introduced into the system, the more likely a catastrophic event is likely
to occur.
Consider
the butterfly effect in the stock market or an online advertising setting. One
computer glitches or has a poor algorithm or for whatever reason decides to dump
its assets. Maybe a few other computers pick up the sale which sends up a red
flag and tells them to sell their assets. This then propagates amongst all of
the computers in a matter of seconds and stocks/auction plummets. Of course if one
sector plummets other sectors are likely to be affected as well and we could
see a market crash or auction crash on the order of minutes. While the stock
market and online sites have taken some measures to try to prevent this such as
‘circuit breakers’ when a stock drops too quickly which will halt the sale of
the stock, the overall affect can still be achieved. Because stocks are not
allowed to reach equilibrium values, the data being used in their algorithms is
inherently flawed and therefore not good practice anyway. Just like the
centipede theory in game theory suggests, humans tend to wait longer and not
necessarily take the instantaneous best choice in a market setting which in
this case actually allows for the market to reach equilibrium and therefore
potentially increase their profits. Computers however act upon thresholds and
data and not upon feelings and instinct so they have no regard for anything but
the algorithm with which they were programmed.
Other
than a lack of market equilibrium, the other problem that arises with computer
trading is a lack of understanding of what exactly is going on. The more sophisticated
a program is, the more likely a bug or unintended effect may be present. With
stock trading computers looking at hundreds of different factors such as price and
trends at time, the reliability and understanding of how all these different
algorithms act with one another or even how your own program will act based on
several changes in market conditions is still largely an unknown. However, the
potential for vast sums of money to be made quickly makes the risk acceptable
to many. However, without a true understanding of how each of these programs
really work and how they work together, they are leaving the chance that the
entire system may be unstable and given a specific input condition, the entire
market could crash.
If we
want to use automated computers to buy and sell stocks/run auctions in the future,
we need to either slow down the rate at which they are able to make
transactions with the market or we need to gain a much deeper understanding of
how the market behaves based on these extremely quick changes in market
conditions.
Google's New Privacy Policy
In recent years the Internet has become a critical part of the way we live our lives. People are now doing a wide range of tasks including shopping, watching television, and chatting with friends and family on the web. In an age where everything is done online and is recordable, one of the constant issues is privacy preservation. The amount of data stored, as well as the way it is stored, is constantly discussed by industry insiders as well as critics. On January 24th the web juggernaut Google announced a massive overhaul to their privacy policies for most of their services. Instead of having a different policy for each service, Google has created one policy that will serve all of its services and go into effect March 1st. Those interested in reading the new Policy should check out the link at the end of this post.
In response to the announcement, several Lawmakers around the world have called on Google to delay the implementation of the new policy so that it can be further studied. Despite the challenges raised by the chair of the European Union’s Data Protection Working Party, Google has announced that it plans to move forward with its plan. Personally, I have no issue with the proposed plan and think that simplifying the policies will make it clearer to users what is actually being done with their data. Even if a policy is overreaching initially it can be easily changed and likely will be if there is sufficient public backlash. Googles goal of making policies clearer is a step in the right direction.
Sources
Google’s New Privacy Policy: http://www.google.com/intl/en/policies/privacy/
Wall Street Journal Article: http://online.wsj.com/article/BT-CO-20120203-712502.html
Further Reading
http://googleblog.blogspot.com/2012/01/updating-our-privacy-policies-and-terms.html
http://news.cnet.com/8301-1009_3-57373694-83/group-sues-ftc-over-googles-planned-privacy-update/
In response to the announcement, several Lawmakers around the world have called on Google to delay the implementation of the new policy so that it can be further studied. Despite the challenges raised by the chair of the European Union’s Data Protection Working Party, Google has announced that it plans to move forward with its plan. Personally, I have no issue with the proposed plan and think that simplifying the policies will make it clearer to users what is actually being done with their data. Even if a policy is overreaching initially it can be easily changed and likely will be if there is sufficient public backlash. Googles goal of making policies clearer is a step in the right direction.
Sources
Google’s New Privacy Policy: http://www.google.com/intl/en/policies/privacy/
Wall Street Journal Article: http://online.wsj.com/article/BT-CO-20120203-712502.html
Further Reading
http://googleblog.blogspot.com/2012/01/updating-our-privacy-policies-and-terms.html
http://news.cnet.com/8301-1009_3-57373694-83/group-sues-ftc-over-googles-planned-privacy-update/
How Twitter is Connected
With the rise of the social network came the ability for people to connect with anybody, anywhere. Post a thought on Twitter one day, and anybody, anywhere in the world, can read it online regardless of distance, country, or language. So is it surprising that these factors still affect the connectivity of Twitter?
Researchers at the University of Toronto have looked into the influence of geographical location, air travel, national boundaries, and languages on connections made in Twitter, highlighting the importance of existing face to face relationships to the connectivity of the social network.
The most obvious factor influencing the connectivity of Twitter is geographical proximity. The largest clusters in Twitter are roughly the size of metropolitan areas - in order of size these clusters are, not surprisingly, New York City, Los Angeles, Tokyo, London, and Sao Paolo, with more than half of the top 25 clusters in the United States. This relationship with geography is due possibly to similar concerns from being in the same neighborhood or from just knowing people nearby.
For larger distances, frequency of air travel between cities better correlates to whether or not two Twitter users are connected. The easier it is to fly from one place to another, the more likely it is for two people in these cities to personally know each other. Therefore, it is also more likely for them to be connected on Twitter.
,
The last two factors are national boundaries and language. Obviously, most clusters exist in countries with more Internet access - and people from less advanced countries are more likely to follow people from the advanced countries because their well being is likely affected by the decisions and actions of those countries. Next, of course, English is the predominant language on Twitter and most people follow users who tweet in English or their own native language.
Overall, this paper is important because it shows the importance of physical social interactions even in the virtual world of social networks. Despite the entire world being available to everyone, we still connect similarly on the web as we do in person.
Sources:
"Geography of Twitter Networks" by Yuri takhteyev, Anatoliy Gruzd, and Barry Wellman
http://homes.chass.utoronto.ca/~wellman/publications/index.html
Researchers at the University of Toronto have looked into the influence of geographical location, air travel, national boundaries, and languages on connections made in Twitter, highlighting the importance of existing face to face relationships to the connectivity of the social network.
The most obvious factor influencing the connectivity of Twitter is geographical proximity. The largest clusters in Twitter are roughly the size of metropolitan areas - in order of size these clusters are, not surprisingly, New York City, Los Angeles, Tokyo, London, and Sao Paolo, with more than half of the top 25 clusters in the United States. This relationship with geography is due possibly to similar concerns from being in the same neighborhood or from just knowing people nearby.
For larger distances, frequency of air travel between cities better correlates to whether or not two Twitter users are connected. The easier it is to fly from one place to another, the more likely it is for two people in these cities to personally know each other. Therefore, it is also more likely for them to be connected on Twitter.
,
The last two factors are national boundaries and language. Obviously, most clusters exist in countries with more Internet access - and people from less advanced countries are more likely to follow people from the advanced countries because their well being is likely affected by the decisions and actions of those countries. Next, of course, English is the predominant language on Twitter and most people follow users who tweet in English or their own native language.
Overall, this paper is important because it shows the importance of physical social interactions even in the virtual world of social networks. Despite the entire world being available to everyone, we still connect similarly on the web as we do in person.
Sources:
"Geography of Twitter Networks" by Yuri takhteyev, Anatoliy Gruzd, and Barry Wellman
http://homes.chass.utoronto.ca/~wellman/publications/index.html
Subscribe to:
Comments (Atom)